Case Study: Pointers & Bytes
A large part of the allure of Haskell is its elegant, high-level ADTs that ensure that programs won’t be plagued by problems like the infamous SSL heartbleed bug.1 However, another part of Haskell’s charm is that when you really really need to, you can drop down to low-level pointer twiddling to squeeze the most performance out of your machine. But of course, that opens the door to the heartbleeds.
Wouldn’t it be nice to have our cake and eat it too? Wouldn’t it be great if we could twiddle pointers at a low-level and still get the nice safety assurances of high-level types? Lets see how LiquidHaskell lets us have our cake and eat it too.
HeartBleeds in Haskell
Modern Languages like Haskell are ultimately built upon
the foundation of C. Thus, implementation errors could open
up unpleasant vulnerabilities that could easily slither past the type
system and even code inspection. As a concrete example, let’s look at a
function that uses the ByteString library to truncate
strings:
First, the function packs the string into a low-level
bytestring b, then it grabs the first n
Characters from b and translates them back
into a high-level String. Lets see how the function works
on a small test:
ghci> let ex = "Ranjit Loves Burritos"We get the right result when we chop a valid
prefix:
ghci> chop' ex 10
"Ranjit Lov"But, as illustrated in Figure 1.1, the machine silently reveals (or more colorfully, bleeds) the contents of adjacent memory or if we use an invalid prefix:
ghci> chop' ex 30
"Ranjit Loves Burritos\NUL\201\&1j\DC3\SOH\NUL"
Types against Overflows Now that we have stared the
problem straight in the eye, look at how we can use LiquidHaskell to
prevent the above at compile time. To this end, we decompose the system
into a hierarchy of levels (i.e. modules). Here, we have three
levels:
- Machine level
Pointers - Library level
ByteString - User level
Application
Our strategy, as before, is to develop an refined API for each level such that errors at each level are prevented by using the typed interfaces for the lower levels. Next, let’s see how this strategy lets us safely manipulate pointers.
Low-level Pointer API
To get started, let’s look at the low-level pointer API that is offered by GHC and the run-time. First, let’s see who the dramatis personae are and how they might let heartbleeds in. Then we will see how to batten down the hatches with LiquidHaskell.
Pointers are an (abstract) type Ptr a
implemented by GHC.
-- | A value of type `Ptr a` represents a pointer to an object,
-- or an array of objects, which may be marshalled to or from
-- Haskell values of type `a`.
data Ptr a
Foreign Pointers are wrapped pointers that can
be exported to and from C code via the Foreign
Function Interface.
data ForeignPtr a
To Create a pointer we use
mallocForeignPtrBytes n which creates a Ptr to
a buffer of size n and wraps it as a
ForeignPtr
mallocForeignPtrBytes :: Int -> ForeignPtr a
To Unwrap and actually use the ForeignPtr
we use
withForeignPtr :: ForeignPtr a -- pointer
-> (Ptr a -> IO b) -- action
-> IO b -- resultThat is, withForeignPtr fp act lets us execute a action
act on the actual Ptr wrapped within the
fp. These actions are typically sequences of
dereferences, i.e. reads or writes.
To Dereference a pointer, i.e. to read or update the
contents at the corresponding memory location, we use peek
and poke respectively. 2
peek :: Ptr a -> IO a -- Read
poke :: Ptr a -> a -> IO () -- Write
For Fine Grained Access we can directly shift pointers
to arbitrary offsets using the pointer arithmetic operation
plusPtr p off which takes a pointer p an
integer off and returns the address obtained shifting
p by off:
plusPtr :: Ptr a -> Int -> Ptr b
Example That was rather dry; let’s look at a concrete
example of how one might use the low-level API. The following function
allocates a block of 4 bytes and fills it with zeros:
While the above is perfectly all right, a small typo could easily slip past the type system (and run-time!) leading to hard to find errors:
A Refined Pointer API
Wouldn’t it be great if we had an assistant to helpfully point out the error above as soon as we wrote it? 3 We will use the following strategy to turn LiquidHaskell into such an assistant:
- Refine pointers with allocated buffer size,
- Track sizes in pointer operations,
- Enforce pointer are valid at reads and writes.
To Refine Pointers with the size of their
associated buffers, we can use an abstract measure, i.e. a
measure specification without any underlying
implementation.
-- | Size of `Ptr`
measure plen :: Ptr a -> Int
-- | Size of `ForeignPtr`
measure fplen :: ForeignPtr a -> IntIt is helpful to define aliases for pointers of a given size
N:
type PtrN a N = {v:Ptr a | plen v = N}
type ForeignPtrN a N = {v:ForeignPtr a | fplen v = N}
Abstract Measures are extremely useful when we don’t
have a concrete implementation of the underlying value, but we know that
the value exists. Here, we don’t have the value – inside
Haskell – because the buffers are manipulated within C. However, this is
no cause for alarm as we will simply use measures to refine the API, not
to perform any computations. 4
To Refine Allocation we stipulate that the size
parameter be non-negative, and that the returned pointer indeed refers
to a buffer with exactly n bytes:
mallocForeignPtrBytes :: n:Nat -> ForeignPtrN a n
To Refine Unwrapping we specify that the
action gets as input, an unwrapped Ptr whose size
equals that of the given ForeignPtr.
withForeignPtr :: fp:ForeignPtr a
-> (PtrN a (fplen fp) -> IO b)
-> IO bThis is a rather interesting higher-order specification.
Consider a call withForeignPtr fp act. If the
act requires a Ptr whose size exceeds
that of fp then LiquidHaskell will flag a (subtyping) error
indicating the overflow. If instead the act requires a
buffer of size less than fp then it is always safe to run
the act on a larger buffer. For example, the below variant
of zero4 where we only set the first three bytes is fine as
the act, namely the function \p -> ..., can
be typed with the requirement that the buffer p has size
4, even though only 3 bytes are actually
touched.
To Refine Reads and Writes we specify that they can
only be done if the pointer refers to a non-empty (remaining) buffer.
That is, we define an alias:
type OkPtr a = {v:Ptr a | 0 < plen v}that describes pointers referring to non-empty buffers (of
strictly positive plen), and then use the alias to
refine:
peek :: OkPtr a -> IO a
poke :: OkPtr a -> a -> IO ()In essence the above type says that no matter how arithmetic was used to shift pointers around, when the actual dereference happens, the size remaining after the pointer must be non-negative, so that a byte can be safely read from or written to the underlying buffer.
To Refine the Shift operations, we simply check that
the pointer remains within the bounds of the buffer, and update
the plen to reflect the size remaining after the shift: 5
plusPtr :: p:Ptr a -> off:BNat (plen p) -> PtrN b (plen p - off)using the alias BNat, defined as:
type BNat N = {v:Nat | v <= N}
Types Prevent Overflows Lets revisit the zero-fill
example from above to understand how the refinements help detect the
error:
Lets read the tea leaves to understand the above error:
Error: Liquid Type Mismatch
Inferred type
VV : {VV : Int | VV == ?a && VV == 5}
not a subtype of Required type
VV : {VV : Int | VV <= plen p}
in Context
zero : {zero : Word8 | zero == ?b}
VV : {VV : Int | VV == ?a && VV == (5 : int)}
fp : {fp : ForeignPtr a | fplen fp == ?c && 0 <= fplen fp}
p : {p : Ptr a | fplen fp == plen p && ?c <= plen p && ?b <= plen p && zero <= plen p}
?a : {?a : Int | ?a == 5}
?c : {?c : Int | ?c == 4}
?b : {?b : Integer | ?b == 0}The error says we’re bumping p up by
VV == 5 using plusPtr but the latter
requires that bump-offset be within the size of the buffer
referred to by p, i.e. VV <= plen p.
Indeed, in this context, we have:
p : {p : Ptr a | fplen fp == plen p && ?c <= plen p && ?b <= plen p && zero <= plen p}
fp : {fp : ForeignPtr a | fplen fp == ?c && 0 <= fplen fp}that is, the size of p, namely plen p
equals the size of fp, namely fplen fp (thanks
to the withForeignPtr call). The latter equals to
?c which is 4 bytes. Thus, since the offset
5 is not less than the buffer size 4,
LiquidHaskell cannot prove that the call to plusPtr is
safe, hence the error.
Assumptions vs Guarantees
At this point you ought to wonder: where is the code for
peek, poke or
mallocForeignPtrBytes and so on? How can we be sure that
the types we assigned to them are in fact legitimate?
Frankly, we cannot as those functions are
externally implemented (in this case, in C), and
hence, invisible to the otherwise all-seeing eyes of LiquidHaskell.
Thus, we are assuming or trusting that those functions
behave according to their types. Put another way, the types for the
low-level API are our specification for what low-level pointer
safety. We shall now guarantee that the higher level modules
that build upon this API in fact use the low-level function in a manner
consistent with this specification.
Assumptions are a Feature and not a bug, as they let us
to verify systems that use some modules for which we do not have the
code. Here, we can assume a boundary specification, and then
guarantee that the rest of the system is safe with respect to
that specification. 7
ByteString API
Next, let’s see how the low-level API can be used to implement to implement ByteStrings, in a way that lets us perform fast string operations without opening the door to overflows.
A ByteString is implemented as a record of three
fields:
bPtris a pointer to a block of memory,bOffis the offset in the block where the string begins,bLenis the number of bytes from the offset that belong to the string.
These entities are illustrated in Figure 1.2; the green portion represents the actual
contents of a particular ByteString. This representation
makes it possible to implement various operations like computing
prefixes and suffixes extremely quickly, simply by pointer
arithmetic.
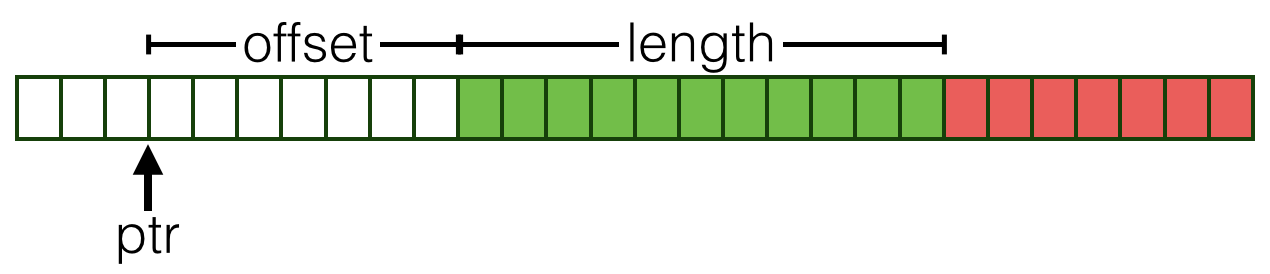
In a Legal ByteString the start
(bOff) and end (bOff + bLen) offsets
lie inside the buffer referred to by the pointer bPtr. We
can formalize this invariant with a data definition that will then make
it impossible to create illegal ByteStrings:
The refinements on bOff and bLen correspond
exactly to the legality requirements that the start and end of the
ByteString be within the block of memory referred
to by bPtr.
For brevity let’s define an alias for
ByteStrings of a given size:
Legal Bytestrings can be created by directly using the
constructor, as long as we pass in suitable offsets and lengths. For
example,
creates a valid ByteString of size 5;
however we need not start at the beginning of the block, or use up all
the buffer, and can instead create ByteStrings whose length
is less than the size of the allocated block, as shown in
good2 whose length is 2 while the allocated
block has size 5.
Illegal Bytestrings are rejected by LiquidHaskell. For
example, bad1’s length is exceeds its buffer size, and is
flagged as such:
Similarly, bad2 does have 2 bytes but
not if we start at the offset of 2:
Exercise: (Legal ByteStrings): Modify the definitions
of bad1 and bad2 so they are accepted
by LiquidHaskell.
Measures are generated from Fields in the datatype
definition. As GHC lets us use the fields as accessor functions, we can
refine the types of those functions to specify their behavior
to LiquidHaskell. For example, we can type the (automatically generated)
field-accessor function bLen so that it actually returns
the exact size of the ByteString argument.
To Safely Create a ByteString the
implementation defines a higher order create function, that
takes a size n and accepts a fill action, and
runs the action after allocating the pointer. After running the action,
the function tucks the pointer into and returns a
ByteString of size n.
Exercise: (Create): Why does LiquidHaskell
reject the following function that creates a
ByteString corresponding to "GHC"?
Hint: The function writes into 3 slots starting at
p. How big should plen p be to allow this?
What type does LiquidHaskell infer for p above? Does it
meet the requirement? Which part of the specification or
implementation needs to be modified so that the relevant
information about p becomes available within the
do-block above? Make sure you figure out the above before
proceeding.
To Pack a String into a
ByteString we simply call create with the
appropriate fill action:8
Exercise: (Pack): We can compute the size of a
ByteString by using the function: Fix the specification for
pack so that (it still typechecks!) and furthermore, the
following QuickCheck style property is
proved.
Hint: Look at the type of length, and
recall that len is a numeric
measure denoting the size of a list.
The magic of inference ensures that pack
just works. Notice there is a tricky little recursive loop
go that is used to recursively fill in the
ByteString and actually, it has a rather subtle type
signature that LiquidHaskell is able to automatically infer.
Exercise: (Pack Invariant): Still, we’re here to learn,
so can you write down the type signature for the
pLoop so that the below variant of pack is
accepted by LiquidHaskell (Do this without cheating by peeping
at the type inferred for go above!)
Hint: Remember that len xs denotes the
size of the list xs.
Exercise: (Unsafe Take and Drop): The functions
unsafeTake and unsafeDrop respectively extract
the prefix and suffix of a ByteString from a given
position. They are really fast since we only have to change the offsets.
But why does LiquidHaskell reject them? Can you fix the specifications
so that they are accepted?
Hint: Under what conditions are the returned
ByteStrings legal?
To Unpack a ByteString into a plain old
String, we essentially run pack in reverse, by
walking over the pointer, and reading out the characters one by one till
we reach the end:
Exercise: (Unpack): Fix the specification for
unpack so that the below QuickCheck style property is
proved by LiquidHaskell.
Hint: You will also have to fix the specification of
the helper go. Can you determine the output refinement
should be (instead of just true?) How big is the
output list in terms of p, n and
acc.
Application API
Finally, let’s revisit our potentially “bleeding” chop
function to see how the refined ByteString API can prevent
errors. We require that the prefix size n be less than the
size of the input string s:
Overflows are prevented by LiquidHaskell, as it rejects
calls to chop where the prefix size is too large which is
what led to the overflow that spilled the contents of memory after the
string (cf. Figure 1.1). In the code below,
the first use of chop which defines ex6 is
accepted as 6 <= len ex but the second call is rejected
as 30 > len ex.
Fix the specification for chop so that the following
property is proved:
Exercise: (Checked Chop): In the above, we know
statically that the string is longer than the prefix, but what if the
string and prefix are obtained dynamically, e.g. as inputs from
the user? Fill in the implementation of ok below to ensure
that chop is called safely with user specified values:
Nested ByteStrings
For a more in-depth example, let’s take a look at group,
which transforms strings like "foobaaar" into
lists of strings like ["f","oo", "b", "aaa", "r"].
The specification is that group should produce a
- list of non-empty
ByteStrings, - the sum of whose lengths equals that of the input string.
Non-empty ByteStrings are those whose length is
non-zero:
We can use these to enrich the API with a null check
This check is used to determine if it is safe to extract the head and
tail of the ByteString. we can use refinements to ensure
the safety of the operations and also track the sizes. 9
The Group` function recursively calls
spanByte to carve off the next group, and then returns the
accumulated results:
The first requirement, that the groups be non-empty is captured by
the fact that the output is a [ByteStringNE]. The second
requirement, that the sum of the lengths is preserved, is expressed by a
writing a numeric measure:
SpanByte does a lot of the heavy lifting. It uses
low-level pointer arithmetic to find the first position in the
ByteString that is different from the input character
c and then splits the ByteString into a pair
comprising the prefix and suffix at that point. (If you filled in the
relevant type signatures above, the below code should typecheck even
after you delete the assume from the
specification.)
LiquidHaskell infers that 0 <= i <= l and
therefore that all of the memory accesses are safe. Furthermore, due to
the precise specifications given to unsafeTake and
unsafeDrop, it is able to prove that the output pair’s
lengths add up to the size of the input ByteString.
Recap: Types Against Overflows
In this chapter we saw a case study illustrating how measures and refinements enable safe low-level pointer arithmetic in Haskell. The take away messages are that we can:
- compose larger systems from layers of smaller ones,
- refine APIs for each layer, which can be used to
- design and validate the layers above.
We saw this recipe in action by developing a low-level
Pointer API, using it to implement fast
ByteStrings API, and then building some higher-level
functions on top of the ByteStrings.
The Trusted Computing Base in this approach includes
exactly those layers for which the code is not available, for
example, because they are implemented outside the language and accessed
via the FFI as with mallocForeignPtrBytes and
peek and poke. In this case, we can make
progress by assuming the APIs hold for those layers and verify
the rest of the system with respect to that API. It is important to note
that in the entire case study, it is only the above FFI signatures that
are trusted; the rest are all verified by LiquidHaskell.
Assuming, of course, the absence of errors in the compiler and run-time…↩︎
We elide the
Storabletype class constraint to strip this presentation down to the absolute essentials.↩︎In Vim or Emacs or online, you’d see the error helpfully highlighted.↩︎
This is another ghost specification.↩︎
This signature precludes left or backward shifts; for that there is an analogous
minusPtrwhich we elide for simplicity.↩︎Did you notice that we have strengthened the type of
plusPtrto prevent the pointer from wandering outside the boundary of the buffer? We could instead use a weaker requirement forplusPtrthat omits this requirement, and instead have the error be flagged when the pointer was used to read or write memory.↩︎If we so desire, we can also check the boundary specifications at run-time, but that is outside the scope of LiquidHaskell.↩︎
The code uses
create'which is justcreatewith the correct signature in case you want to skip the previous exercise. (But don’t!)↩︎peekByteOff p iis equivalent topeek (plusPtr p i).↩︎